Load balancing using Kafka
Prerequisite: Basic understanding of Tibco Streambase tool and Apache Kafka
Recently I have been working on one of the PoC, where I want to do load balancing from Kafka broker to multiple TIBCO Streambase client, Since Kafka is all about topic and before I learnt that only queue system supports round robin because Kafka don’t have queue system. So, when I was exploring on this I learned that Kafka support round robin is default partition strategy for producers without using a key. What it means when data is stored in the kafka it is stored in round robin. For example, if we have 3 kafka broker then while producing the data 1st message will be stored in kafka broker 1 and replicated message will be stored in broker 2 and broker 3, for the next subsequent message it will stored the 2nd message first in broker 2 and then replicated message in broker 1 and broker 3. this will continue will till all the message stored by the producer.
How Kafka consumer does load sharing
Kafka consumer consumption divides partitions over consumer instances within a consumer group. each consumer in the consumer group is an exclusive consumer of a “fair share” of partitions. this is how kafka does load balancing of consumers in a consumer group. consumer membership within a consumer group is handled by the kafka protocol dynamically. if new consumers join a consumer group, it gets a share of partitions. if a consumer dies, its partitions are split among the remaining live consumers in the consumer group. this is how kafka does fail over of consumers in a consumer group.
Consumer to partition cardinality — load sharing redux
Only a single consumer from the same consumer group can access a single partition. if consumer group count exceeds the partition count, then the extra consumers remain idle. kafka can use the idle consumers for failover. if there are more partitions than consumer group, then some consumers will read from more than one partition.

notice that server 1 has topic partition p2, p3, and p4, while server 2 has partition p0, p1, and p5. notice that consumer c0 from consumer group a is processing records from p0 and p2. notice that no single partition is shared by any consumer from any consumer group. notice that each partition gets its fair share of partitions for the topics.
In our case Tibco Streambase client will be act as consumer for Kafka broker so we need to make sure all the Tibco Streambase application consume the message from same topic using same consumer group id
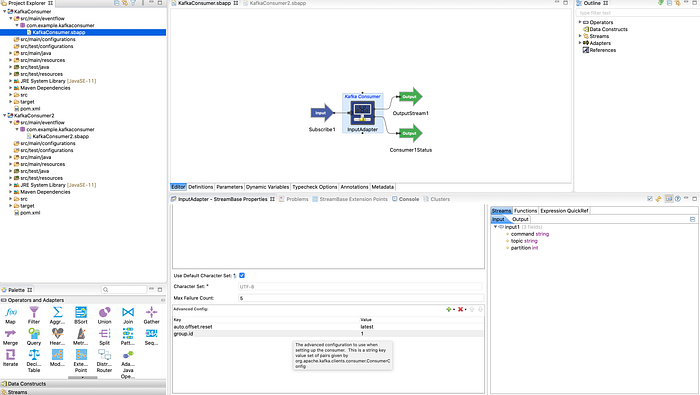
Create simple consumer process in Tibco Streambase as shown below

For demonstration purpose i have used the TIBCO streambase as client but you can you other client for testing purpose. As shown in above screen shot , I have two projects in my workspace, KafkaConsumer and KafkaConsumer2, these projects are to simulate multiple Kafka consumer for Kafka Broker. But make sure when you create topic partition size , It has to be equal to number of consumers otherwise the extra consumers remain idle until another consumer dies.
So, if you need to keep Tibco Streambase Kafka Consumer client in the same consumer group you need to consumer group id for both client id as
Below are the step to do in Tibco Streambase but it is applicable to other client as well
- First You need to select Kafka Consumer Operator (in KafkaConsumer.sbapp file) Streambase properties tab(bottom)
2. Select Advance tab and scroll down to advance config section then
3. Add new property call group.id and value need to be same in all consumer group same as shown in below screen shot.

Conclusion: With this article as you can see it is possible to have round robin distribution from Kafka topic but it has limitation as it needs to have multiple partition then only you can distribute the message otherwise if the number of partitions is 1 and number of consumers are more than one then one of the consumers will be able to consume all the message and other will remain idle until the active consumer dies.